As stated in the INTRODUCTION, the purpose of this project is to extend the binary symetric channel with equally likely input probabilities of 0's and 1's to a binary symetric channel, upon which no equally likelihood limitation is imposed. As mentioned in the PRIOR WORK, the encoding method used by Pradhan and Ramchandran is to form bins using error correcting codes. The syndromes of the error correcting codes, then, are the bin numbers. Our scheme is to use the same procedure with the addition of a system to form codewords with equally likely 0's and 1's at the encoder; and an additional system for prediction at the decoder.
A convenient method to form codewords with equally likely 0's and 1's is to use Huffman coding. This is illustrated in Figure-1 below.
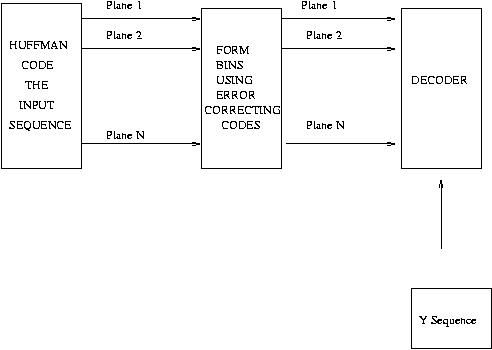
Figure-1) The Introduced Scheme
THE ENCODER:
The inputted 0's and 1's are grouped into groups of a fixed length, M, and these groups are coded using the Huffman code. After this stage, the Huffman coded sequences are separated into bit-planes, first bit-plane being the first bits of the Huffman codes, the second bit-plane being the second bits..., and, each of these bit-planes are processed using an error correcting code.
As an example, assume that the input 0 has a probability of occurence of 0.7, and the input 1 has a probability of occurence of 0.3. Assume that M=2. Then, the Huffman coded groups will be as follows:
M=2 Length Sequences: 00 01 10 11 After Huffman Coding:
Assuming the whole data that need to be transmitted is [001001], the encoding would be as shown:
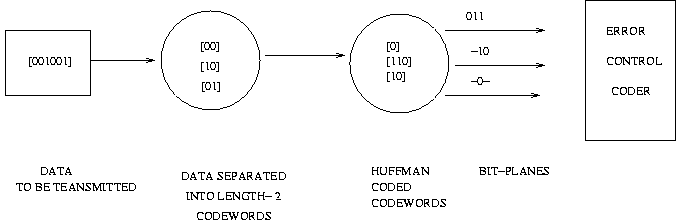
Figure-2) The Encoder
THE DECODER:
The decoder receives a bin number, and the question is how to find out the correct transmitted sequence from the bin number. The bin number represents the group of sequences, one of which is the correct transmitted sequence. The decoding process works by first finding the best estimate of the transmitted sequence, X, through Y, the noisy sequence present at the decoder. This estimate is obtained by:
(i) Computing the probability of each possible transmitted sequence, given Y and the noise distribution.
(ii) Choosing the sequence with the highest conditional probability of transmission as the best estimate of X.
(iii) Selecting the correct X as the bin member, which is closest to the best estimate found in part (ii).
(iv) For each bit plane after the first bit plane, the probability calculation is done by additionally conditioning on the previously decoded bit-planes. (Thus, the decoding is done in order from the first bit-plane of the Huffman code to the last one. )
ABSTRACT
INTRODUCTION
PRIOR WORK
BASIC SCHEME
METHODOLOGY
RESULTS
CONCLUSIONS
REFERENCES